![]()
Purpose of Research / Background of Requirements
In the context of customizing the Kubernetes persistent volume CSI driver, and dividing a large NFS file system into multiple smaller persistent volumes (PVs), how to ensure that each persistent volume only uses up to the capacity limit of the volume (for example, 50GB) is a technical challenge that needs to be addressed.
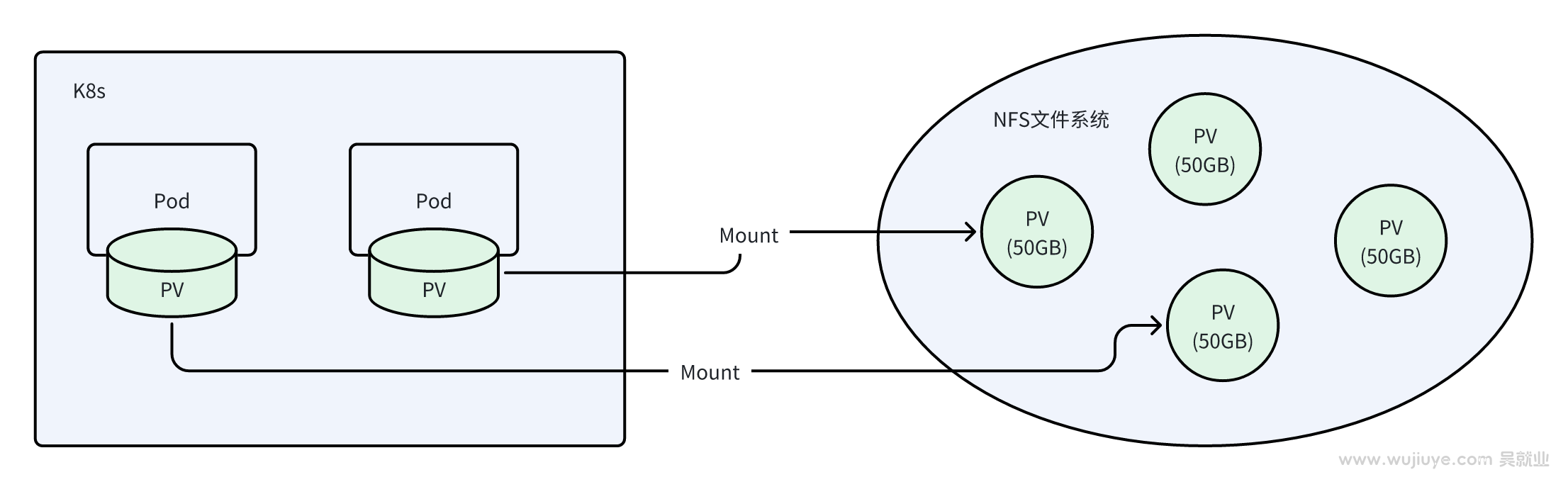
Scheme Research
Scheme One: eBPF Interception of vfs_write
vfs_write is a system function of the Linux virtual file system for write operations on files. All write operations on files must go through this system function.
eBPF can run sandboxed programs within the Linux operating system kernel to safely and effectively extend the kernel’s capabilities. Without changing the kernel source code or loading kernel modules, it can insert our hook logic.
Demo case for verification:
//go:build ignore
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include <asm-generic/errno.h>
// ......
SEC("kprobe/vfs_write")
int kprobe_vfs_write(struct pt_regs *ctx) {
// .......
struct dir_cfg *value = bpf_map_lookup_elem(&dir_allow_write_map, &key);
if (value && value->disable == 1) {
bpf_printk("not allow write by root path = /%s\n", root_path);
return -EPERM;
}
// ........
return 0;
}
char __license[] SEC("license") = "Dual MIT/GPL";
Research conclusion: No matter whether we return -1 or 0 or 1, we cannot prevent the execution of vfs_write. The reason is that we cannot block the call of the system function in the eBPF program. It’s like the AOP logic can only keep a diary.
Scheme Two: eBPF + NFS Protocol Interception of Write Operations
All disk write operations are ultimately communicated to the NFS file system through the network via the NFS protocol. Can eBPF intercept the network traffic data packets? Then decode the NFS data packets according to the NFS v3 protocol using the rpc communication protocol and xdr encoding and decoding protocol, and perform rewriting or packet dropping on the write operation data packets.
NFS protocol: https://www.ietf.org/rfc/rfc1813.txt
Nfs’s rpc communication protocol: https://linux-nfs.org/wiki/index.php/NetworkTracing
After analyzing the packet capture with tcpdump, it is found that the process of writing a file is:
- Open a file for writing: LOOKUP -> WRITE -> COMMIT
- Create a file for writing: LOOKUP -> CREATE -> WRITE -> COMMIT
The LOOPUP process is to obtain the file handle step by step.
For example: Suppose we need to open the /data/logs/log.txt file for writing.
Then you need to go through three LOOPUPs to get the desired file handle, which are:
- Call LOOKUP to query the data directory in the current directory and obtain the file handle of the data directory.
- Call LOOKUP to query the logs directory in the data directory and obtain the file handle of the logs directory.
- Call LOOKUP to query the log.txt file in the logs directory and obtain the file handle of the log.txt file.
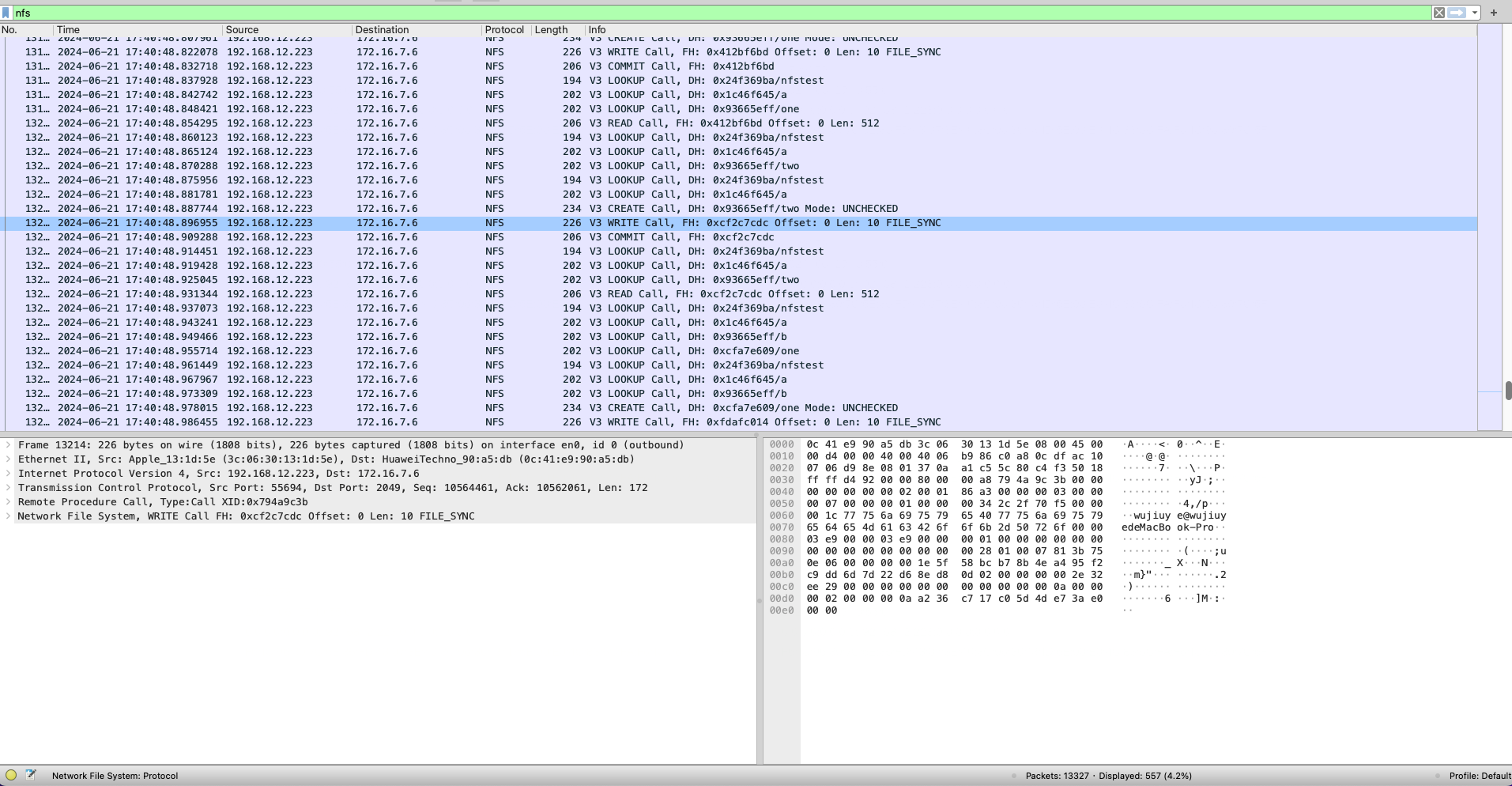
Research conclusion: Since we can only get the file handle of the file being written in the NFS protocol, we cannot directly determine which directory this file is under. Want to intercept the NFS network data packet through eBPF to intercept the write, because it is necessary to know which directory a file handle is in, it requires a great cost to cache the file metadata information, and it is not feasible to spend a lot of money just to implement an interception function.
Scheme Three: eBPF XDP or TC Direct Matching IP Packet Dropping
In the worst case, can we only allow a pod to hang a PV, and we can obtain the pod corresponding to the source IP through the IP protocol layer data packet, and then check the PV hung by the pod. If this PV has reached the write limit, then can we directly drop the packet in the eBPF interception?
Since the eBPF XDP mounting point can only intercept incoming network data packets, that is to say, intercepting the write has actually been completed by the NFS server, and only the response is intercepted, which may lead to data inconsistency?
So another plan was given priority, using TC to implement the interception of outgoing traffic and match the source Pod IP packet dropping. TC is short for Traffic Control, which is a powerful set of tools and frameworks in the Linux kernel for traffic control and is a subsystem of the kernel. Reference literature: Understanding TC eBPF’s Direct-Action (DA) Mode (2020)
The plan has limitations: TC cannot control NFS reading and writing, that is to say, if packet dropping is processed for a certain pod, it will affect reading and writing. But normally, a disk is full, should only affect writing and not affect reading, nor affect deletion.
On the k8s DemainSet pod, the feasibility of using the TC packet dropping scheme was verified, and the conclusion was drawn: Since the PV is mounted by the CSI driver’s node component of this pod, only this pod has installed the NFS client, which can interact with the NFS file system, and then the node component is to mount this directory to the application pod’s mount point, in fact, we are writing data to the disk in the application pod, and finally, the network is written to the NFS file system through the CSI node component’s NFS client. So we can’t intercept the application Pod, only the CSI node component’s pod.
That is: All IP-based interception schemes are not feasible. The TC plan is also not feasible.
Scheme Four: eBPF LSM Intercepting vfs_write
LSM is short for Linux Security Module, which is a hook-based framework in the Linux kernel for implementing security policies and mandatory access control.
Linux 5.7 introduced eBPF LSM (short for LSM BPF). eBPF LSM is an extension of LSM, allowing developers to write eBPF programs to define and execute security policies.
Because this hook allows us to return non-zero to block the system call, it can be used to implement the interception of file writing. From the source code of the vfs_write system function, we found the file_permission hook.
The file_permission hook is used to check the file permissions before accessing the opened file. The definition of this hook is as follows:
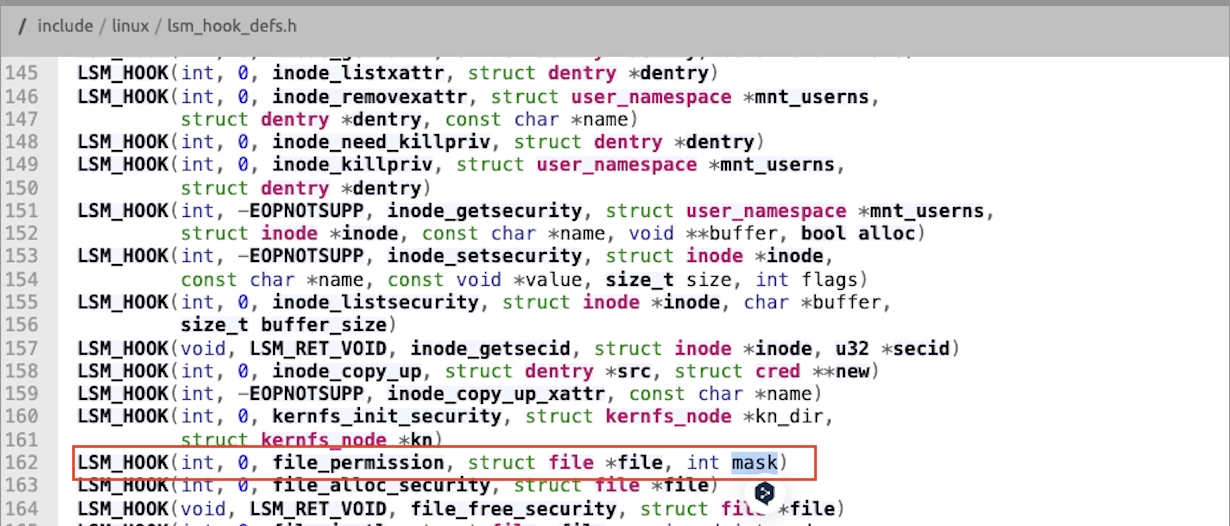
Parameter Description:
- @file contains the file structure being accessed.
- @mask contains the requested permissions.
- If the permissions are authorized, return 0, otherwise return others.
But vfs_read also calls this hook, and other places like open also call this hook. It is necessary to be able to distinguish which system function is called in order to implement this plan theoretically.
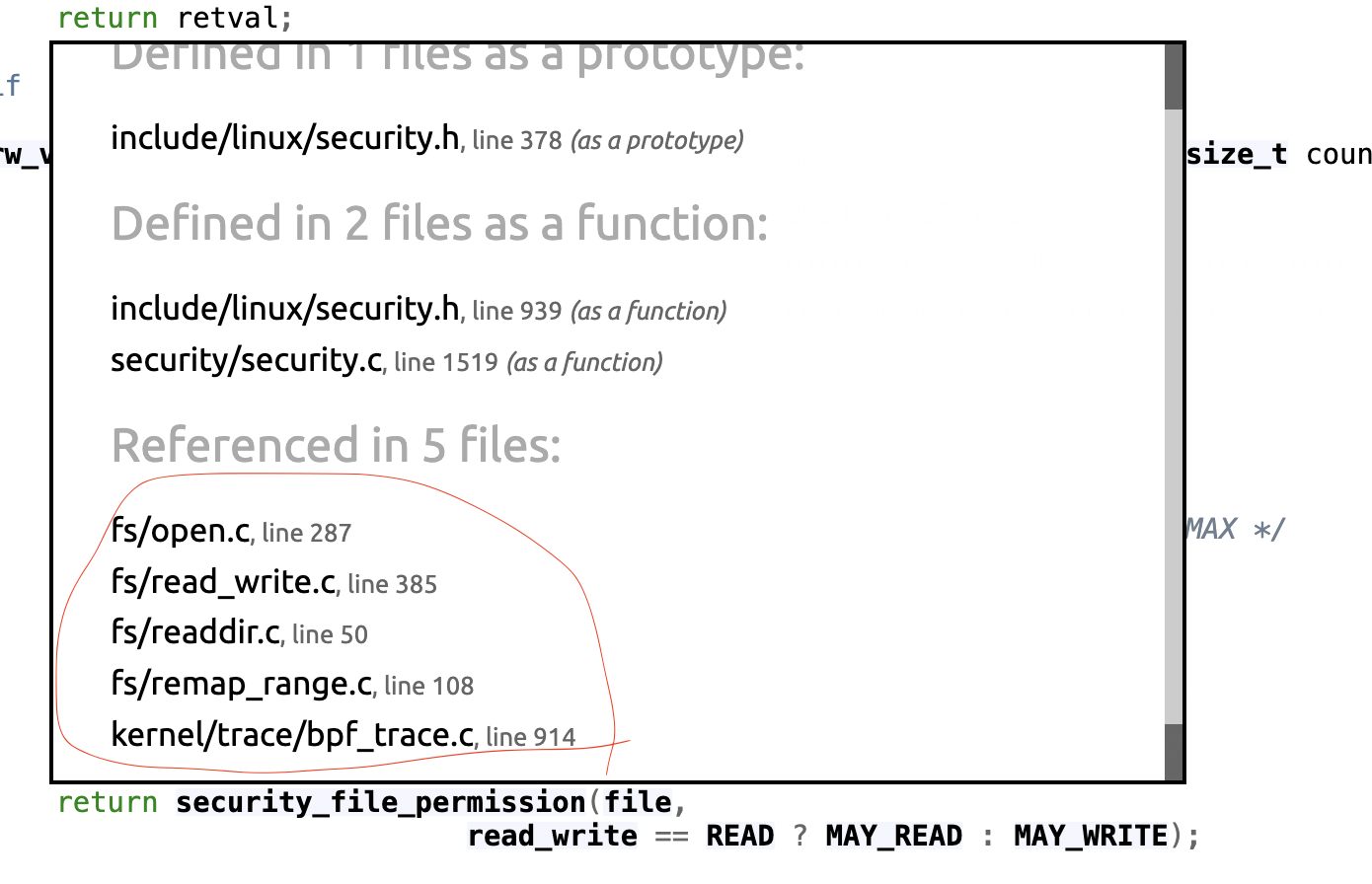
Using eBPF Linux Security Module to Patch Linux Kernel Security Vulnerabilities in Real Time This article introduces how to get the number of the system call from the rax register. Then, the rax value corresponding to the write system call = 1 was found in Searchable Linux Syscall Table.
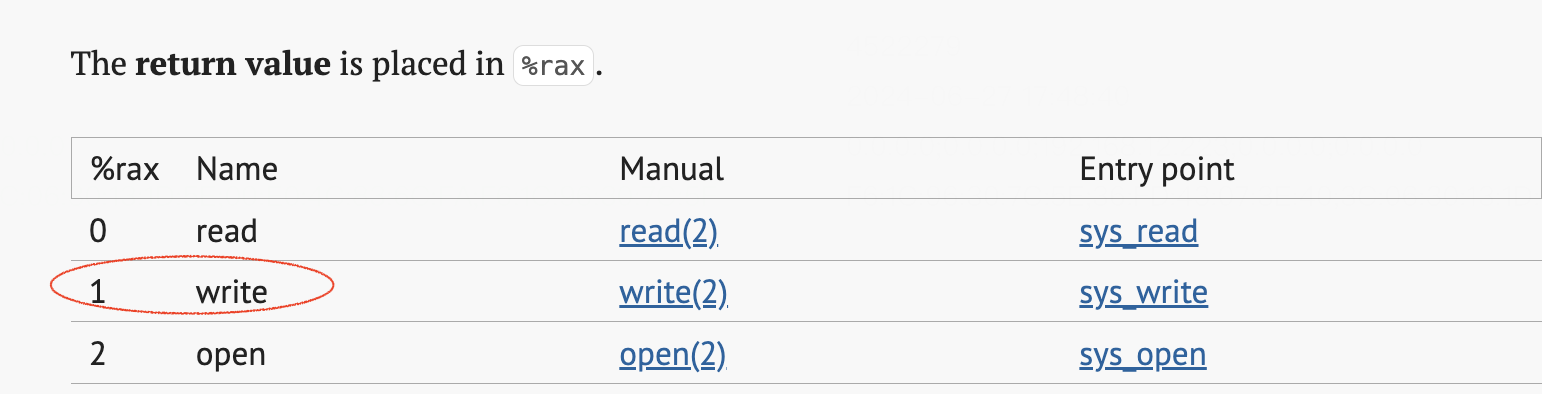
Verification bpf code:
//go:build ignore
#include <vmlinux.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#define X86_64_WRITE_SYSCALL 1
#define WRITE_SYSCALL X86_64_WRITE_SYSCALL
char __license[] SEC("license") = "Dual MIT/GPL";
SEC("lsm/file_permission")
int BPF_PROG(handle_file_permission,struct file *file, int mask, int ret) {
struct pt_regs *regs;
struct task_struct *task;
int syscall;
task = bpf_get_current_task_btf();
regs = (struct pt_regs *) bpf_task_pt_regs(task);
// In x86_64 orig_ax has the syscall interrupt stored here
syscall = regs->orig_ax;
if (syscall != WRITE_SYSCALL){
return 0;
}
// todo implementation returns -1 based on the file path
struct dentry *dentry = BPF_CORE_READ(&file->f_path,dentry);
const unsigned char *filename;
filename = BPF_CORE_READ(dentry,d_name.name);
char filename_str[256];
int name_len = bpf_probe_read_kernel_str(filename_str, sizeof(filename_str), filename);
// Simple judgment first verify the plan
if (name_len>8 && filename_str[0]=='t'&& filename_str[1]=='e') {
bpf_printk("block write...%s",filename_str);
return -1;
}
return 0;
}
Validation results:
Failed to write file using vim:
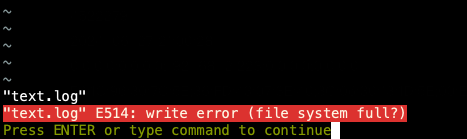
Output log:

Research Conclusion
After evaluating various approaches, implementing file write interception using eBPF LSM stands out as the most viable solution in terms of performance and feasibility.
Research Process Output Related Articles:
- How to Use eBPF-Go: A Practical Case Study of Intercepting vfs_read Function to Output File Names
- eBPF-Go C Structure and Go Structure Mapping
- How to Develop Locally in Golang and Then Compile and Run Remotely
- A Slightly More Complex eBPF-Go Learning Case: Hooking vfs_write Write Operation
- NFS Protocol Analysis of the Write File Process
- NFS Protocol’s RPC Communication Protocol
- NFS Protocol RPC Communication Packet Decoding: What Are the First Four Bytes?
- Understanding Linux Kernel Network Traffic Control Tools tc (Traffic Control) with Pictures
- Experiment: Can tc Intercept Traffic from Other Pods on the Same Node in a Demoset Pod?
- Implementing Blocking Write File Operation with eBPF LSM