![]()
Why Use Multiple Databases in redis? Our project has been using it this way, and I also don’t understand this point. If business isolation is needed, then a prefix can be added to the cache key for different businesses. If this leads to excessively long keys, a large redis cluster can be divided into multiple clusters corresponding to different businesses. No matter how many databases are divided, the total memory size of the cluster remains the same, and the amount of data that can be stored is also the same. Why not divide a large cluster for each business to use?
Since business isolation is needed, divide a large redis cluster for use by different businesses, and divide it according to the cache size requirements and concurrent access volume of different businesses, which can better achieve business isolation. Isolating with different databases is not a big problem, but if the services are not divided by business, this method will cause the project to switch databases every time it operates redis, adding an extra network I/O for the service, reducing the performance of cache read and write, and the more concurrent volume, the more problems it shows, which is contrary to high concurrency performance tuning.
In java projects, in addition to jedis supporting dynamic database switching, other frameworks either modify the connection pool configuration dynamically or configure a connection pool for each database, and all of these will affect performance, so jedis has become the best choice. Why don’t these frameworks support dynamic database switching? Because no one uses it this way, obviously, dynamic database switching is not recommended.
I saw a post on the Google online forum Redis DB forum, link: https://groups.google.com/forum/?spm=a2c4e.11153987.0.0.1d6e4e37polahb#!forum/redis-db.
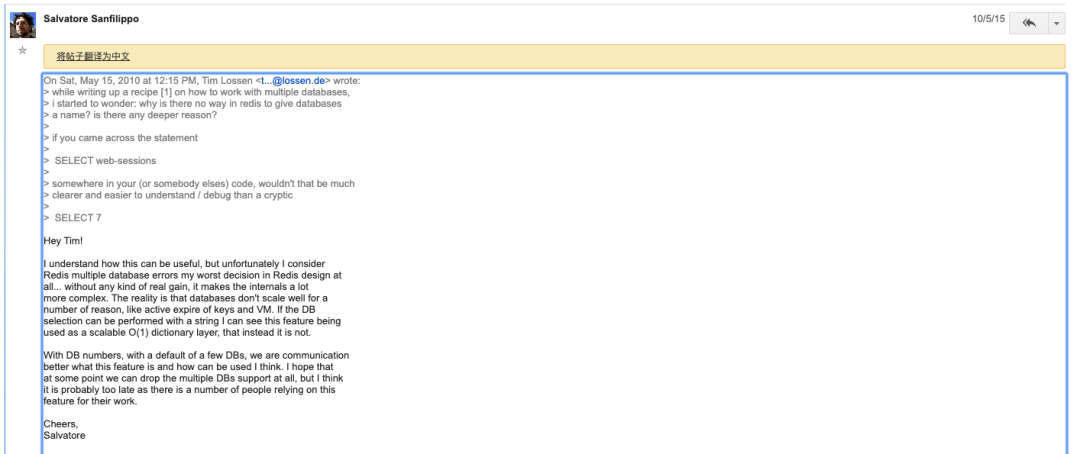
The figure shows redis author antirez replying to a post by tim lossen in a post titled database names?. In the post, tim lossen asked why redis multi-database does not support the use of names, but can only use numbers? As you can see in the picture, the reply from redis author antirez roughly means: The multi-database of Redis is the worst decision I made in the design of Redis. I hope that to some extent, we can give up the support of multiple databases, but I think it may be too late, because many people are using this feature in their work.
In previous redis articles, I also mentioned that when configuring the connection pool with jedis, it is recommended to turn off the configuration that sends a ping command to the server to check if the connection is available every time a connection is obtained from the connection pool. Because in high concurrency scenarios, this operation will cause the service to frequently send ping commands to the redis server, and it will also cause the service itself to be equivalent to an additional get request time, because of network I/O.
The project is not divided by business, leading to serious coupling between various projects, and the use of multiple databases has further increased the difficulty of project maintenance and increased the communication cost between groups, and “What is the key, in which database?” has also become our common language in communication. When you want to modify a certain key, you need to ask the opinions of various groups, and all projects need to be modified, and when you want to add a key, you need to ask various groups, whether this key has been used, to avoid covering someone else’s key. Of course, this is also the biggest mistake at the system architecture level. However, apart from the system architecture issues, it is obviously more appropriate to use different libraries than to isolate business with multiple databases, whether by adding key prefixes or using multiple clusters.